Introduction:
DEP Watershed Monitoring program holds a wealth of sampled water and sediment chemistry data. One particular analyte, Cadmium (Cd), is a toxic metal that is found naturally in soil, however it is also a component used in automobile brake pads. An exploratory investigation was attmempted, with the intentions of correlating lake and stream sediment-laden cadmium levels with population density. After numerous failed attempts of importing this dataset into R and GeoDa, this preliminary review of spatial autocorrelation is abandoned and alternative chosen. The new investigation will attempt to examine the spatial distribution of cadmium levels across the state of Florida.
Examination:
- Plot the raw data
- Plot the emperical variogram
- Develop a reasonable variogram model
- Use model together with the data to create a surface
- Examine model diagnostics
Default kriging interpolation:
 [Basic kriging geostatistical interpolation]
[Basic kriging geostatistical interpolation]  [Same surface with station location distribution]
[Same surface with station location distribution] This simple surface does a moderatly decent job of modeling the phosphate belt in west central Florida, extending east of Hillsborough County, as well as similar areas of phosphate mines around the big bend.
Check for dataset normality:
The histogram shows significant skewness. Extreme outliers -- especially the single 17.2 mg/kg -- might need to be removed to observe a more appropriate distribution of analyte values across the dataset, though I'll leave it in for now
 [Histogram shows significant skewness]
[Histogram shows significant skewness] The QQPlot further suggests normality is highly suspect. Large portions of the dataset deviate from the mean; low values in particular.

A log transformation is applied to restore normality. Box-Cox transformation provides little variation to the original dataset.
Y(s) = log(Z(s)) for Z(s) ≥ 0
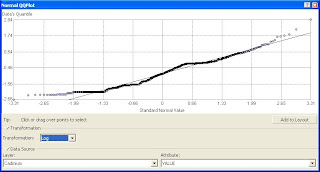 [Log transformation successful in minimizing distance and variation about the mean]
[Log transformation successful in minimizing distance and variation about the mean]
Examine spatial distribution of exceedance values:
 [Phosphate belt modeled from adjacent large values]
[Phosphate belt modeled from adjacent large values]
Explore trend:
Very slight upside down U-shaped trend in east-west direction, and a slightly decreasing planar north-south trend. This is attributed to the unique shape of Florida (as opposed to a more positively correlated distribution possibility in Colorado for instance).

Examine spatial distribution of exceedance values:
 [Phosphate belt modeled from adjacent large values]
[Phosphate belt modeled from adjacent large values] Explore trend:
Very slight upside down U-shaped trend in east-west direction, and a slightly decreasing planar north-south trend. This is attributed to the unique shape of Florida (as opposed to a more positively correlated distribution possibility in Colorado for instance).

[Occurrences of values across Florida]
 [Alternative view]
[Alternative view] Examine spatial autocorrelation:
 [Semivariogram of the cadmium dataset]
[Semivariogram of the cadmium dataset] Semivariogram cloud:
- x-axis = lad distance (distance separating each pair)
- y-axis = difference
- Closer locations should be similar
- Distance between location pairs should increase with semivariogram values
- Cloud should flatten out after certain distance; indicates that a relationship between pairs of locations is no longer correlated
- This model experiences significant flattening and inaccuracy; could be alleviated with the removal of the 17.2 outlier
Remove Trend:
- Use a second order log transformation to remove trend in the northwest-to-southeast direction
- Use anisotropy to assist in removing directional components to spatial autocorrelation: the variogram increases more gradually and flattens out
 [Values are attempted to be kept close to the mean]
[Values are attempted to be kept close to the mean] Cross validation: Assess the model's performance
- Mean: Close to 0
- RMSE / Average Standard Error: as small as possible
- RMS Standardized Error: Close to 1
 [Measuring model's performace]
[Measuring model's performace] The 17.2 outlier increases difficulty in judging lower values distribution about the mean, however the lower values are a decent fit.
Results:
Compare cross validation between the original, and fitted model. The map below is then clipped to the state of Florida.
 [Cross validation comparison and final interpolated surface]
[Cross validation comparison and final interpolated surface] The fitted model is somewhat more accurate, however this dataset is modeled fairly well with default parameters. This is not the case for other datasets, however. This technique can significantly improve the interpolation of information across space by removing trend, fitting an appropriate model, and finally creating a more reasonable and accurate surface.
Although the levels of cadmium are largely localized, and variable across space, these methods successfully model two important areas of high concentrations of such minerals: the phosphate belt east of Hillsborough county, as well as another region of concentrated mining operations to the north - in the big bend region.

No comments:
Post a Comment